Company
IR
Tokyo, Japan – October 20, 2021– Morpho, Inc. (hereinafter, “Morpho”), a global leader in image processing and imaging AI solutions, announced today that Morpho has published a preprint version of a research paper on a method for accelerating deep learning inference. The preprint is available on the arXiv website.
The research content of this paper is the technology used in “SoftNeuro®”, one of the world’s fastest deep learning inference engines developed and successfully commercialized by Morpho.
“SoftNeuro” is available free of charge on Morpho’s website until December 31, 2021, for non-commercial use (*1). It is used by a wide range of users. We have decided to publish this paper to offer a deeper understanding of the technology for prospective users to enjoy the convenience of innovative product “SoftNeuro”.
All users of the “SoftNeuro” free trial have an opportunity to answer the “User Questionnaire” and receive an `Amazon gift card` worth 1,000 yen. Do not miss this opportunity!
・Free trial service page: https://softneuro.morphoinc.com/index_en.html

・Title: SoftNeuro: Fast Deep Inference using Multi-platform Optimization
・Authors: Masaki Hilaga, Yasuhiro Kuroda, Hitoshi Matsuo, Tatsuya Kawaguchi, Gabriel Ogawa, Hiroshi Miyake and Yusuke Kozawa
・Available at: https://arxiv.org/abs/2110.06037
1. Separation of layers and routines in DNNs (Deep Neural Networks).
2. Accelerated inference by using dynamic programming to find the best combination of routines.
3. Presentation through experiments that faster inference is possible compared to existing inference engines.
DNNs are applied in a variety of fields. While DNN models can be trained on rich computational resources such as GPUs, inference must be done “fast” on limited computational resources such as smartphones, AR/VR devices, and industrial machines. Various inference engines have been released to the public, but they have not been able to perform optimal computation in real-world environments.
“SoftNeuro”, developed by Morpho, optimizes the entire DNN model to achieve high-speed inference in a variety of environments, including CPU, GPU, and DSP. It uses dynamic programming to choose the best among various types (float32, float16, qint8, etc.), image representation format (channels-first and channels-last), and algorithms (Winograd and naive methods).
1. Models trained with various DNN frameworks can be taken in and converted to “SoftNeuro”. Specifically, models can be converted from TensorFlow and ONNX (which can be converted from Caffe2, Chainer, Microsoft Cognitive Toolkit, MXNet, PyTorch, etc.). You can speed up the process by, for example, integrating the ReLU and Batch Normalization layers into the previous layer.
2. The transformed model is tuned to run faster in the inference environment. In doing so, the model is separated into layers of abstract computational concepts and concrete implemental routines. A layer consists of layer parameters indicating computation methods and learned values, i.e. weights. In the case of the Convolution layer, layer parameters refer to stride and padding, and weights refer to kernel and bias. There can be multiple routines that are concrete implementation for a single layer. This is because various routines can be created due to different environments (CPU, GPU, DSP, etc.), different data types (float32, qint8, etc.), and different computation algorithms.
3. The first step in tuning is to measure the execution time of each routine. This is called “profiling.” Based on the results of profiling, appropriate routines in the layer can be selected to enable high-speed inference. The algorithm described below is used to select routines and complete the tuning.
The DNN model consists of a directed acyclic graph with layers as nodes. The possible graph structures include a wide variety of branching patterns (Fig.1). In this complex structure, the best combination of routines that the layer takes must be found. In particular, when data types are changed between routines or data is transferred from CPU to GPU, the type conversion or data transfer process (adapt layer) needs to occur in the interim, which must also be considered.
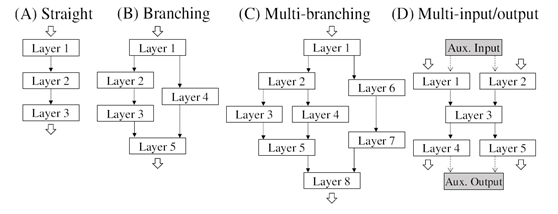
Figure 1
“SoftNeuro” uses a dynamic programming algorithm based on the possible routines and profiling results for each layer to quickly search for the best combination of routines.
1. For each of the VGG16, ResNet50, MobileNetV2, and MobileNetV3 models, tuning was performed in a configuration that allows both float32 and qint8 types, and the inference speed was improved compared to simply using float32 or qint8 routines.
2. Comparison experiments with existing inference engines, such as Tensorflow Lite and PyTorch Mobile, showed that SoftNeuro was the fastest for all the models described above. (Fig.2) (Unit in the figure is ms, measured on a smartphone (Snapdragon 835))
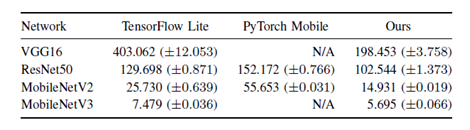
Figure 2
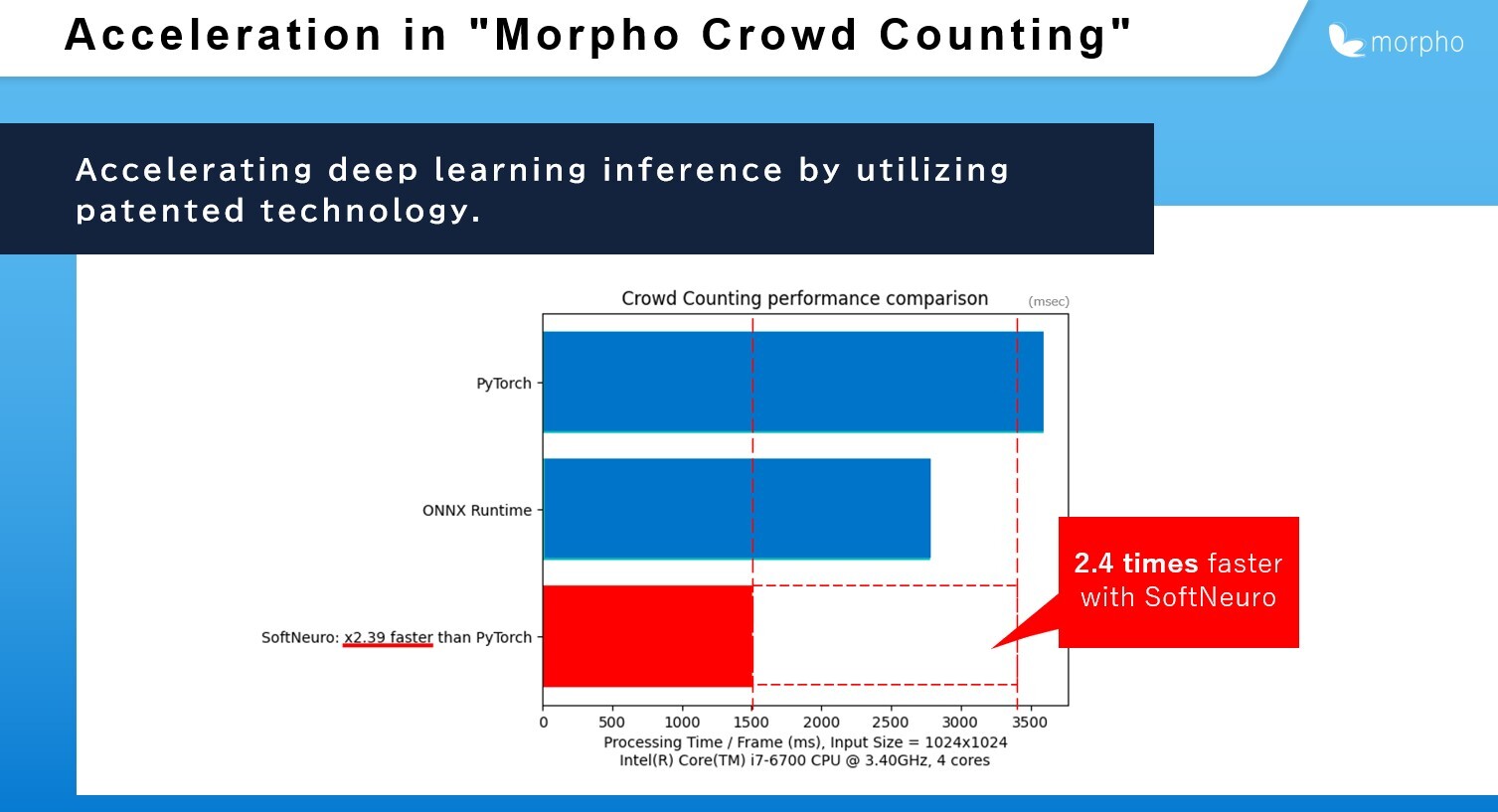
3. When compared to TVM, an inference engine that uses a different tuning method, SoftNeuro outperformed both in terms of tuning speed and inference speed.
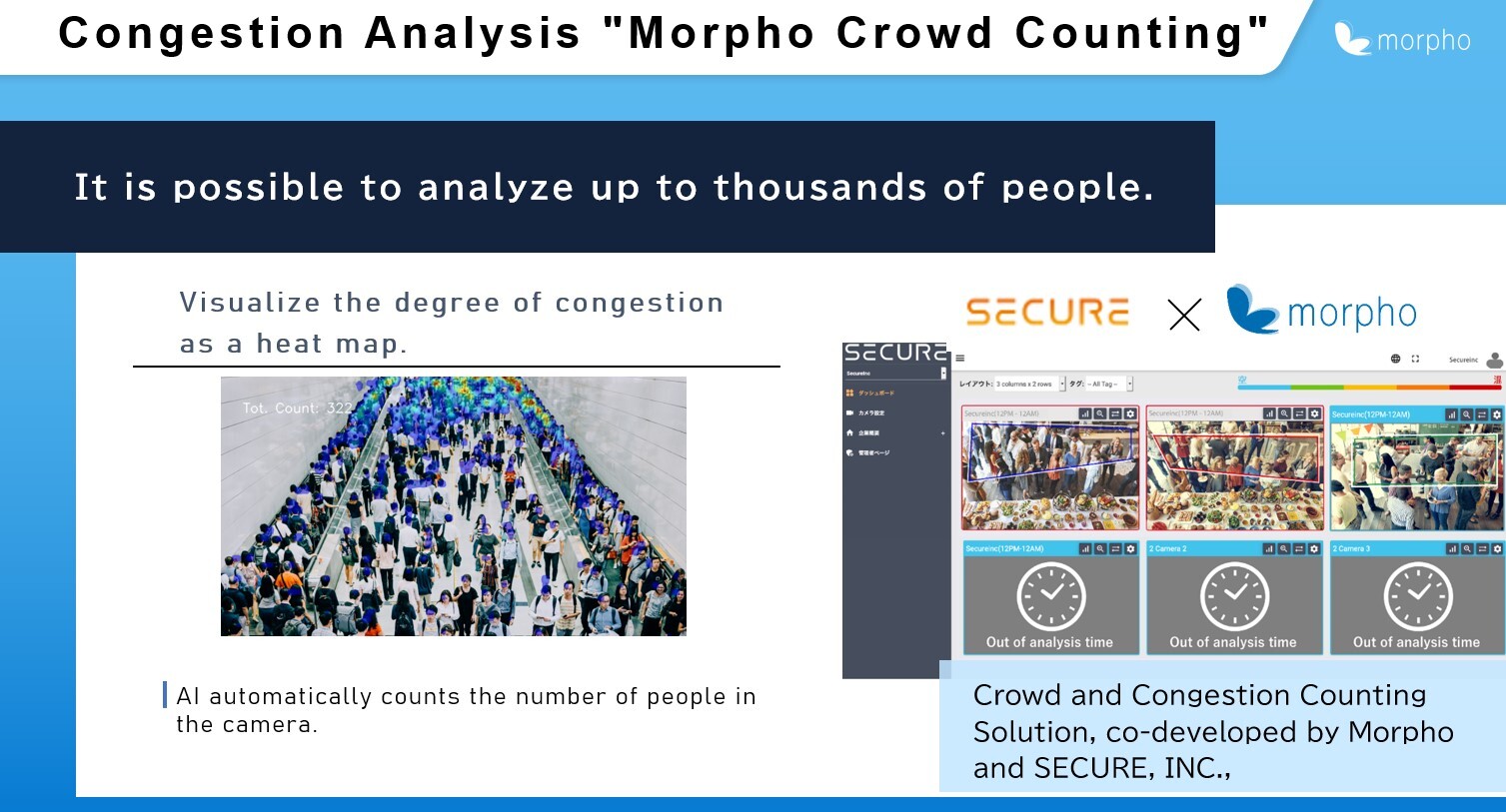
“Crowd and Congestion Counting Solution”, co-developed by Morpho and SECURE, INC., is a video analysis AI that visualizes the degree of crowding and congestion of people. Visualization of this kind of data can be used to avoid crowds and cramped space for safe shopping and dining.
The technology introduced in this paper enables the high-speed and high-accuracy inference required to visualize the degree of congestion in a variety of situations, including commercial facilities and restaurants.
・Related technologies for the solution:
-Deep Learning Inference Engine SoftNeuro: https://www.morphoinc.com/en/technology/sie
-Congestion Analysis “Morpho Crowd Counting™”: https://www.morphoinc.com/en/technology/canalysis
Non-commercial use means the following:
・Payments are not received in any way.
・Developed product is not intended for commercial use.
・Providing commercial services is not intended.
For details, refer to the terms of use (https://softneuro.morphoinc.com/terms_en.html).
If you wish to use the product for commercial use or after the free trial period, contact us at:
softneuro-contact@morphoinc.com
Copyright© Morpho, Inc. All rights reserved.